Skip Lists
Overview
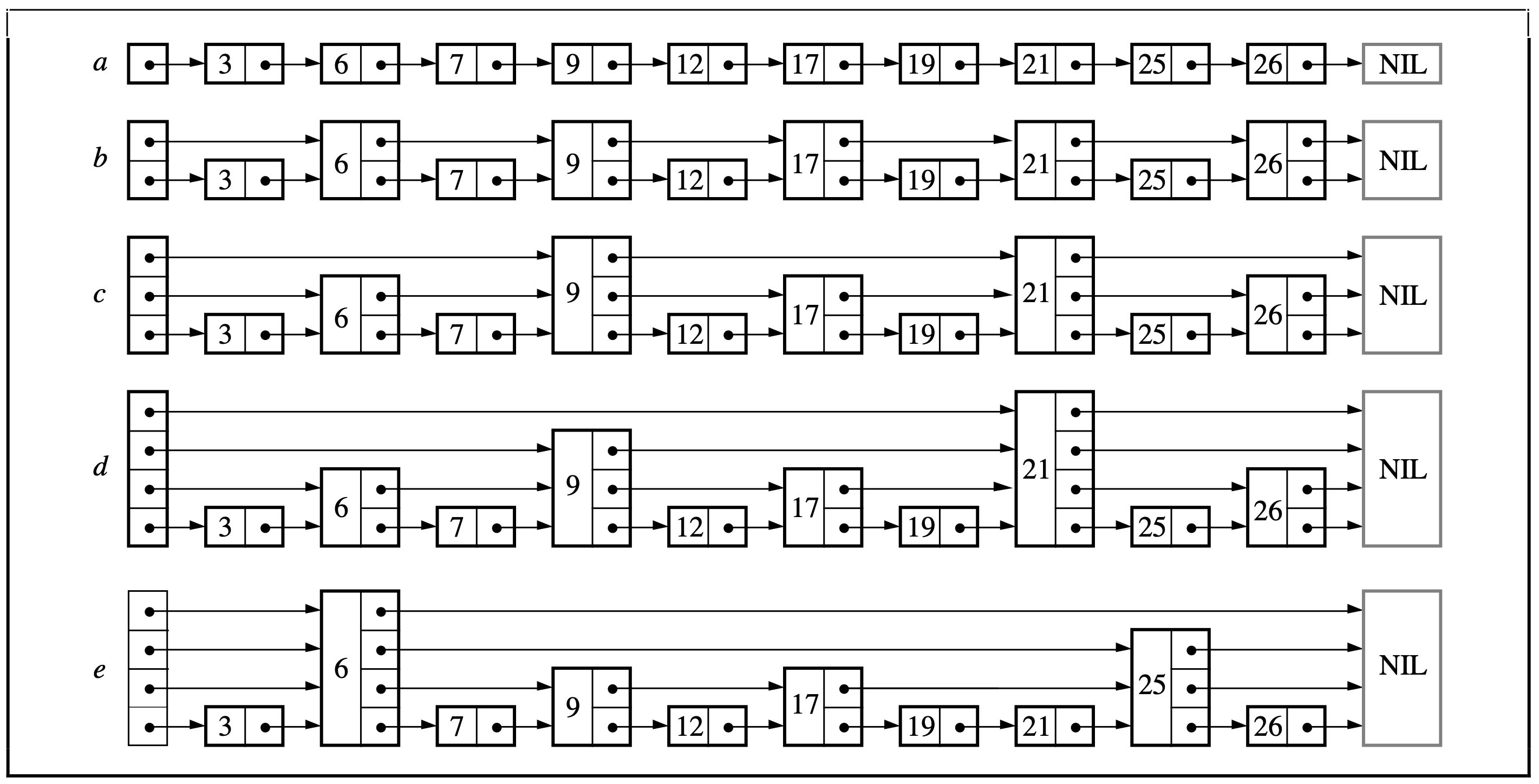
Skip lists are a data structure that can be used in place of balanced trees. Skip lists use probabilistic balancing rather than strictly enforced balancing and as a result the algorithms for insertion and deletion in skip lists are much simpler and significantly faster than equivalent algorithms for balanced trees.
Skip Lists: A Probabilistic Alternative to Balanced Trees
Skip lists were first described in 1989 by William Pugh.
To quote the author:
Skip lists are a probabilistic data structure that seem likely to supplant balanced trees as the implementation method of choice for many applications. Skip list algorithms have the same asymptotic expected time bounds as balanced trees and are simpler, faster and use less space.
William Pugh, Concurrent Maintenance of Skip Lists (1989)
MIT 6.046J Design and Analysis of Algorithms, Spring 2015 (Lecture 7)
Other Resources
Inlab Scheme and Skip Lists
General Representation
Inlab Scheme implements several different skiplist abstract data types. The “main” skiplist is optimised to maintain networking information and SHA256 hashes as a key. The key is 32 bytes large (256 bits) and designed for the purposes:
- SHA256 hashes
- MAC adresses
- MAC address ranges
- IP addresses
- IP address ranges
Available Inlab Scheme Procedures
Use Cases
One important aspect of Inlab Scheme is being an implementation framework and control language for low level networking application and devices.
The power and speed of skip lists are both not restricted or “destroyed” just by making it accessible as an abstract data type on the level of the Scheme interpreter. Other data types, especially the threads abstraction (relying on POSIX threads) can access skip lists at full native “C” speed - meaning “wire speed” for networking devices like switches, routers, interception devices and security devices.
The following use cases for this particular skip list implementation are currently of special interest for us:
Forwarding tables
This skip list implementation - with a few important extensions - used as a forwarding table and CAM (content addressable memory) is much faster than a hash table and O(log n)-robust when the number of MAC addresses become larger. Additionally it allows “hot” altering operations that would otherwise not be feasible.
Routing tables
A skip list containing IP address ranges (an integral and native data type for Inlab Scheme) can be used almost immediately as an ultra fast routing table - practically independent of its size.
ARP/ND6 tables
A skip list is just perfect to store the IPv4 and IPv6 association to MAC addresses (ARP for IPv4 and neighbour discovery for IPv6, abbreviated ND6). In comparison to the commonly used hash tables a skip list has the following advantages:
- Absolutely robust to growth with practically no performance degradation
- Easy editing and deletion capabilities